












Les algorithmes de compression vidéo autres que le M-JPEG sont particulièrement nombreux et recouvrent une variété de formats propriétaires et open source. Les présenter tout ici serait particulièrement fastidieux et peu intéressant. En effet, les différents codecs disponibles appliquent à divers degrés les normes de compression vidéo MPEG définies par le Moving Picture Experts Group, groupe de travail de l'ISO. Ce sont donc ces normes que nous allons examiner en détails, ainsi que les principes qui les sous-tendent.
Quelques remarques préliminaires s'imposent. Tout d'abord, il est nécessaire d'avoir à l'esprit que ces normes dépassent la simple question de la compression pour toucher à d'autres problématiques telle que le mode synchronisation des différents objets (sons et images) qui composent la vidéo, problématiques tout aussi passionnantes mais qui nous écartent quelque peu de notre sujet. Ensuite qu'elles recouvrent une variété de formats qui s'en inspirent de près ou de loin. Enfin qu'elles répondent à une série de besoins spécifiques et ne doivent pas donc être perçues comme de simple améliorations successives d'un modèle original.
Les normes MPEG qui concernent en partie les questions
de compression vidéo sont les suivantes :
La norme MPEG-1 voit le jour en 1992 pour répondre aux besoins croissants d'amélioration des possibilités de stockage liés à l'essor du compact-disc. Le principe à la base du MPEG est qu'en plus de gérer la redondance spatiale présente au sein de chaque image qui compose les séquences vidéo, on va s'appliquer à gérer également la dimension temporelle de la redondance, c'est-à-dire déterminer quelles zones de pixels changent d'une image à l'autre, et lesquelles restent identiques. De ce fait, on peut tenir compte du flux et éviter ainsi de devoir réencoder pour chaque image les mêmes informations que celles de l'image précédente, comme c'est le cas en M-JPEG. Evidemment, le revers de la médaille est que l'accès devient séquentiel et que l'on perd la possibilité de travailler image par image. On comprendra alors pourquoi les techniques de compression MPEG sont essentiellement destinées à la diffusion et non à l'édition.
La compression temporelle repose sur la définition de trois types d'images, au sein d'une séquence vidéo :
- Les images-clé (aussi appelées I-frames en anglais) sont compressées individuellement et indépendamment de leur relation aux autres images de la séquence. L'élimination de la redondance spatiale au sein de l'image se fait au moyen d'une transformée en cosinus discrète (DCT) des blocs de 8x8 pixels qui la composent, suivie d'une quantisation puis d'un codage RLE.
- Les images prédites (aussi appelées P-frames en anglais) sont compressées au moyen du principe dit de compensation de mouvement, qui vise à éliminer la redondance temporelle entre l'image prédite et l'image-clé qui la précède. L'idée est de coder différemment les macroblocs qui composent l'image prédite en fonction du fait qu'ils sont identiques ou différents à ceux de l'image-clé. Les macroblocs qui diffèrent sensiblement sont codés de la même manière qu'un macrobloc dans une image-clé, tandis que ceux qui sont identiques ou presque à ceux de l'image antérieure sont codés référentiellement.
- Les images bidirectionnelles (aussi appelées B-frames en anglais) sont compressées de manière identique aux images prédites. La différence avec celles-ci réside dans le fait que les macroblocs sont codés référentiellement à une image qui précéde ou à une image qui suit. Les images suivantes doivent donc déjà se trouver en mémoire pour que soit réalisée la reconstruction de l'image bidirectionnelle. La très faible quantité de macroblocs qui ne peuvent être référencés soit par une image qui précède, soit par une image qui suit, explique le gain considérable d'espace lors de l'opération de compression.
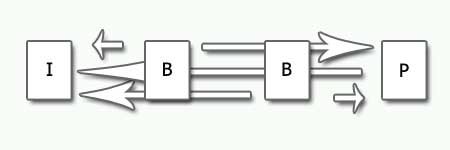
Le flux vidéo est donc compressé de la sorte, en générant une suite d'images du type IBBPBBPBBPBBI.
Le MPEG-2 ne remplace pas à proprement parler
le MPEG-1 mais a été conçu pour
répondre à des besoins différents en
matière de taux de transfert. La vidéo est ici
entrelacée, chaque séquence se composant de deux
trames et non plus d'une simple succession d'images. La compensation de
mouvement se travaille donc ici sur des blocs de 8x16 pixels,
mieux adaptés à ce flux d'informations beaucoup
plus important. Le MPEG-2 est essentiellement utilisée dans
le domaine de la télévision numérique,
ainsi que pour les DVD-Vidéo et SVCD.
La norme MPEG-4 comprend une
variété d'aspects qui dépassent
largement le simple domaine de la compression. Deux parties de la norme
sont spécifiquement consacrée au codage
vidéo : les parties 2 (ASP) et 10 (AVP, cette
dernière sous-tend le H264, au coeur du Quicktime 7
d'Apple). S'inspirant des techniques
précédentes, la norme MPEG-4 développe
une technologie qui lui permet de fournir des
taux de compression exceptionnels dont le principal avantage est de
permettre le transfert d'une vidéo de bonne qualité à faible débit. L'ASP sous-tend
d'excellents codecs gratuits actuels tels le DivX
ou le Xvid
qui offrent une
qualité d'image remarquable pour d'importants taux de
compression. L'AVP est quant à lui un codec vidéo
avancé qui améliore sensiblement le principe de
compensation du mouvement en autorisant jusqu'à 32
images intermédiaires et permet l'utilisation de blocs de
tailles variables (16x16 au 4x4).