
Computer Science Seminars
Université Libre de Bruxelles
Computer Science Department
Many problems can be described using an integer program, e.g. scheduling, capital budgeting, or vehicle routing. In full generality, solving an integer program is known to be NP-hard. However, integer programs where the coefficient matrix is totally unimodular (each determinant of any square submatrix is one of the values in {-1,0,1}) can be solved in polynomial time. One of the central questions in combinatorial optimization is whether there is a polynomial-time algorithm for solving integer programs where the coefficient matrix is totally Δmodular (each determinant of any square submatrix is one of the values in {Δ,....,Δ}). The case of Δ=2 was positively resolved by Artmann, Weismantel, and Zenklusen only as recently as 2017 and the question for larger values of Δ still remains open and appears to be very difficult. In this talk, I will present results for several different cases of the above conjecture. These results require tools from structural graph theory and include a new algorithm for finding a maximum independent set in a graph with bounded odd cycle packing number, as well as a new proximity result of integer optimal solutions and their corresponding linear relaxation solutions.

Yelena Yuditsky is a F.R.S.-FNRS Postdoctoral Fellow at Université libre de Bruxelles. She did her PhD at McGill University under the supervision of Bruce Reed and Sergey Norin. Her research interests are in design and analysis of algorithms, optimization, structural graph theory and discrete geometry.
Each student will follow one seminar from the following topics : algorithms, security, optimization and artificial intelligence. This seminar is classified as algorithms for the purpose of this requirement.

This study utilizes analog quantum computing devices from entities like Canada's D-Wave, France's Pasqal, and America's QuEra. These devices are adept at processing binary, quadratic, and unconstrained optimization problems (QUBO), igniting interest in this model of research. The document will first offer insights into how these machines function from the perspective of a computer scientist and then delve into the realm of universal gate quantum computers, such as those developed by IBM. Subsequently, it will explore a variety of optimization and operational research challenges that are addressed using quantum analog technologies. Among the problems discussed will be the Traveling Salesman Problem (TSP), Capacitated Vehicle Routing Problem (CVRP), Job Shop Scheduling Problem (JSSP), Resource-Constrained Project Scheduling Problem (RCPSP), Max Cut, and 3-Satisfiability Problem (3-Sat). Particularly for 3-Sat, the study demonstrates how employing polynomial-time reduction to the Maximum Independent Set (MIS) can streamline problem-solving by producing a new, though sparser graph with more variables. It's crucial to take into account the specific configurations of these quantum machines, such as the incomplete qubit graph, during this process.
Each student will follow one seminar from the following topics : algorithms, security, optimization and artificial intelligence. This seminar is classified as optimization for the purpose of this requirement.

Decisions made through predictive algorithms sometimes reproduce inequalities that are already present in society. Is it possible to create a data mining process that is aware of fairness? Are algorithms biased because humans are? Or is this the way machine learning works at its most fundamental level? In this lecture, I will give an overview of some of the main results in fairness-aware machine learning, the research field that tries to answer these questions.

Toon Calders is a professor in the computer science department of the University of Antwerp in Belgium. He is an active researcher in the area of data mining and machine learning. He is editor of the data mining journal, and has been program chair of a number of data mining and machine learning conferences, including ECML/PKDD 2014 and Discovery Science 2016. Toon Calders was one of the first researchers to study how to measure and avoid algorithmic bias in machine learning and is one of the editors of the book “Discrimination and Privacy in the Information Society - Data Mining and Profiling in Large Databases”, published by Springer in 2013. He is currently leading a group of 4 researchers studying theoretical aspects of fairness in machine learning, as well as looking into practical use cases in collaboration with Flemish tax authorities, public welfare organizations, and an insurance company.
Each student will follow one seminar from the following topics : algorithms, security, optimization and artificial intelligence. This seminar is classified as artificial intelligence for the purpose of this requirement.

Trusted Execution Environments (TEEs) can provide strong security guarantees in distributed systems, and even protect embedded software in the IoT or in critical control systems. Measuring the passage of time and taking actions based on such measurements is a common security-critical operation in many of these systems. Yet, few TEEs combine security with real-time processing and availability, or provide hard guarantees on the timeliness of code execution. A key difficulty here is that TEEs execute within an effectively untrusted environment, which can influence expectations on time and progress. In this talk, I will present our research on categorising approaches to tracking the passage of time in TEEs, highlighting the respective dependability guarantees. Focusing first on the popular Intel SGX architecture, we analyse to what extend time can be securely measured and utilised. We then broaden the scope to other popular trusted computing solutions and list common applications for each notion of time and progress, concluding that not every use case requires an accurate access to real-world time. Following this, I will present a configurable embedded security architecture that provides a notion of guaranteed real-time execution for dynamically loaded enclaves. We implement preemptive multitasking and restricted atomicity on top of strong enclave software isolation and attestation. Our approach allows the hardware to enforce confidentiality and integrity protections, while a decoupled small enclaved scheduler software component can enforce availability and guarantee strict deadlines of a bounded number of protected applications, without necessarily introducing a notion of priorities amongst these applications.
Jan Tobias Muehlberg works as a professor at ULB and as an associate researcher at KULeuven DistriNet Research Group. He researches topics involving privacy, safety and security of information and communication systems, with particular interest in dependable embedded systems and secure critical ICT infrastructures, and in interdisciplinary research on questions around the responsible and sustainable development and use of ICTs. Jan Tobias is specifically interested in societal aspects of security and privacy in dependable systems, in trusted execution environments, and in security architectures for safety-critical embedded systems. Before joining ULB, Jan Tobias worked as a research manager at KU Leuven (BE), a researcher at the University of Bamberg (DE), obtained a Ph.D. from the University of York (UK) and worked as a researcher at the University of Applied Sciences in Brandenburg (DE), where he also acquired his Master’s degree in Computer Science.
Each student will follow one seminar from the following topics : algorithms, security, optimization and artificial intelligence. This seminar is classified as security for the purpose of this requirement.
 In this talk we will discuss the role and benefits deck functions can
have in symmetric cryptography. We will illustrate this with concrete
modes for (authenticated) encryption on top of these, as well as with
examples of efficient designs of such functions.
In this talk we will discuss the role and benefits deck functions can
have in symmetric cryptography. We will illustrate this with concrete
modes for (authenticated) encryption on top of these, as well as with
examples of efficient designs of such functions.
Modern symmetric encryption and/or authentication schemes consist of modes of block ciphers. Often these schemes have a proof of security on the condition that the underlying block cipher behave as (strong) pseudo-random permutations ((S)PRP), that is, when keyed with a fixed and unknown key it shall be hard to distinguish from a random permutation. The PRP and SPRP security notions have become so accepted that they are referred to as the standard model. (S)PRP security cannot be proven but thanks to this nice split in primitives and modes, the assurance of block-cipher based cryptographic schemes relies on public scrutiny of the block cipher in the simple standard scenario.
During the last decade, however, permutation-based cryptography has gained a lot of traction. Modes on top of these primitives have appeared and many new permutations have been proposed. At their core, these modes often have a duplex-like construction and its parallel nephew, farfalle. However, while it is reasonable to assume one can build a block cipher that is (S)PRP secure, it is impossible to formalize what it means for a permutation to behave like an ideal permutation.
We show that permutation-based cryptography can have its own standard model with (keyed) duplex functions or farfalle-based functions at their center: Both are instances of what we call deck functions, and the standard model is the pseudorandom function (PRF) security. Modes can be defined in terms of deck functions and can be proven secure in the setting where the keyed deck function is hard to distinguish from a random oracle. Similarly to the (S)PRP security of a block cipher, the PRF security of a deck function is the subject of public scrutiny and cryptanalysis.
Since March 2015, Joan Daemen is full professor symmetric cryptography at Radboud University Nijmegen in the Digital Security (DiS) Group. He is currently at the head of the DiS group. Until 2018, he worked also as a security architect and cryptographer for STMicroelectronics, previously Proton World (1998-2003), previously Banksys (1996-1998), all that time in the security engineering group. He did a PhD on the design of symmetric cryptography at COSIC in Leuven from 1988 until 1995.
Gilles Van Assche currently works in the Secure Microcontrollers Division of STMicroelectronics and teach cryptography at the ULB and at the École Supérieure d'Informatique in Brussels. He got a Physics Engineer degree and a PhD degree from the Université Libre de Bruxelles (ULB). After working for several years in quantum cryptography and information theory, his current research is in (classical) symmetric cryptography, mainly in collaboration with Joan Daemen, Michaël Peeters and, since 2006, Guido Bertoni. This collaboration spans several nice projects, such as the introduction of the concept of cryptographic sponge functions and the design of the Keccak sponge function, which was selected as the new SHA-3 standard in 2012, after an intense five-year contest. He is also interested in side-channel attacks, which were explicitly taken into account from the start of the design of Keccak.
Each student will follow one seminar from the following topics : algorithms, security, optimization and artificial intelligence. This seminar is classified as security for the purpose of this requirement.
 Kidney exchange programs (KEPs) increase kidney transplantation by facilitating the exchange of incompatible donors. Increasing the scale of KEPs leads to more opportunities for transplants. Collaboration between transplant organizations (agents) is thus desirable. As agents are primarily interested in providing transplants for their own patients, collaboration requires balancing individual and common objectives. In this talk, we consider ex-post strategic behavior, where agents can modify a proposed set of kidney exchanges. We introduce the class of rejection-proof mechanisms, which propose a set of exchanges such that agents have no incentive to reject them, such mechanisms are closely related to Nash-equilibria in Integer Programming games. We provide an exact mechanism and establish that the underlying optimization problem is S2P-hard; we also describe computationally less demanding heuristic mechanisms. We show rejection-proofness can be achieved at a limited cost for typical instances. Furthermore, our experiments show that the proposed rejection-proof mechanisms also remove incentives for strategic behavior in the ex-ante setting, where agents withhold information.
Link to paper
Kidney exchange programs (KEPs) increase kidney transplantation by facilitating the exchange of incompatible donors. Increasing the scale of KEPs leads to more opportunities for transplants. Collaboration between transplant organizations (agents) is thus desirable. As agents are primarily interested in providing transplants for their own patients, collaboration requires balancing individual and common objectives. In this talk, we consider ex-post strategic behavior, where agents can modify a proposed set of kidney exchanges. We introduce the class of rejection-proof mechanisms, which propose a set of exchanges such that agents have no incentive to reject them, such mechanisms are closely related to Nash-equilibria in Integer Programming games. We provide an exact mechanism and establish that the underlying optimization problem is S2P-hard; we also describe computationally less demanding heuristic mechanisms. We show rejection-proofness can be achieved at a limited cost for typical instances. Furthermore, our experiments show that the proposed rejection-proof mechanisms also remove incentives for strategic behavior in the ex-ante setting, where agents withhold information.
Link to paper
Each student will follow one seminar from the following topics : algorithms, security, optimization and artificial intelligence. This seminar is classified as optimization for the purpose of this requirement.
 Problems related to processing and storing large datasets arising from sociology, infrastructures, biology, or other natural sciences became increasingly important in the last decades and a lot of scientific and engineering efforts have been dedicated to this direction. A general way to model problems arising in these fields is via set systems (also called as concept classes or hypergraphs). Formally, a set system is a pair (X,S), where X is a set and S is a collection of subsets of X.
In this talk, we will review some of the classical methods to approximate set systems. We discuss tight bounds for uniform random sampling and then we will focus on the key algorithmic tool of the talk: perfect matchings with low crossing numbers. Matchings and spanning paths with low crossing numbers were introduced by Welzl (1988) for geometric range searching. Since then, they became a key structure in computational geometry and have found many other applications in various fields such as discrepancy theory, algorithmic graph theory, or learning theory.
In the second part of the talk, we will discuss a simple, randomized algorithm which given a set system with dual VC-dimension d, constructs a matching of X with crossing number Õ(|X|1-1/d) in time O(|X|(1/d)|S|), improving upon the previous-best construction of time Õ(|X|2|S|). This contribution allows us to obtain improved algorithms for constructing low-discrepancy colorings and ε-approximations of sub-quadratic size. Our method does not use any input-specific tools, which makes it capable to handle abstract set systems and geometric set systems in high dimensions, without additional complications. The presented results are joint work with Nabil Mustafa and were published in SoCG 2021.
Problems related to processing and storing large datasets arising from sociology, infrastructures, biology, or other natural sciences became increasingly important in the last decades and a lot of scientific and engineering efforts have been dedicated to this direction. A general way to model problems arising in these fields is via set systems (also called as concept classes or hypergraphs). Formally, a set system is a pair (X,S), where X is a set and S is a collection of subsets of X.
In this talk, we will review some of the classical methods to approximate set systems. We discuss tight bounds for uniform random sampling and then we will focus on the key algorithmic tool of the talk: perfect matchings with low crossing numbers. Matchings and spanning paths with low crossing numbers were introduced by Welzl (1988) for geometric range searching. Since then, they became a key structure in computational geometry and have found many other applications in various fields such as discrepancy theory, algorithmic graph theory, or learning theory.
In the second part of the talk, we will discuss a simple, randomized algorithm which given a set system with dual VC-dimension d, constructs a matching of X with crossing number Õ(|X|1-1/d) in time O(|X|(1/d)|S|), improving upon the previous-best construction of time Õ(|X|2|S|). This contribution allows us to obtain improved algorithms for constructing low-discrepancy colorings and ε-approximations of sub-quadratic size. Our method does not use any input-specific tools, which makes it capable to handle abstract set systems and geometric set systems in high dimensions, without additional complications. The presented results are joint work with Nabil Mustafa and were published in SoCG 2021.
Each student will follow one seminar from the following topics : algorithms, security, optimization and artificial intelligence. This seminar is classified as algorithms for the purpose of this requirement.
 Game theory is a robust framework for modeling decision-making processes in various systems,
spanning from biological organisms to human societies. When applied to human interactions, it
gains substantial depth and accuracy through empirical observations and behavioral experiments.
In this talk, we will focus on the integration of game theory and experimental data, with a clear
emphasis on the development of theoretical models. Our presentation will feature experiments
conducted within our research group, showcasing their applicability to a range of topics, including
trading in networks and cooperative behavior. We will discuss the outcomes of these experiments
and illustrate how they inform the development of precise theoretical models. This talk offers an
informative exploration of the intersection between theoretical constructs and real-world human
behavior, providing valuable insights for academic colleagues and emphasizing our commitment to
proposing advanced theoretical models grounded in empirical findings.
Game theory is a robust framework for modeling decision-making processes in various systems,
spanning from biological organisms to human societies. When applied to human interactions, it
gains substantial depth and accuracy through empirical observations and behavioral experiments.
In this talk, we will focus on the integration of game theory and experimental data, with a clear
emphasis on the development of theoretical models. Our presentation will feature experiments
conducted within our research group, showcasing their applicability to a range of topics, including
trading in networks and cooperative behavior. We will discuss the outcomes of these experiments
and illustrate how they inform the development of precise theoretical models. This talk offers an
informative exploration of the intersection between theoretical constructs and real-world human
behavior, providing valuable insights for academic colleagues and emphasizing our commitment to
proposing advanced theoretical models grounded in empirical findings.
Carlos Gracia (Getxo, Spain, 1970) moved to Zaragoza in 1974, where he has lived ever since. After several years working in the city council, he attended the National Distance Education University of Spain, obtaining his BS in Physics in 2006. Then, he earned an MSc in Physics from the University of Zaragoza and a Ph.D. in Physics at the Department of Condensed Matter Physics of the University of Zaragoza in 2012, with a thesis entitled Dynamics and Collective Phenomena of Social Systems. From 2012 onwards, Carlos has been a researcher within the Complex Systems and Networks Lab (COSNET) and a member of the Institute for Biocomputation and Physics of Complex Systems (BIFI) at the University of Zaragoza. Carlos's research pursuits encompass Evolutionary Game Theory, Social Dynamics, Biophysics, and Complex Networks. Notably, his recent projects are centered around applying Physics and Mathematics to Social Sciences and Biology, specifically focusing on uncovering the intricate mechanisms that underlie social and economic behavior. His work spans theoretical and experimental investigations, particularly in understanding cooperation dynamics within human communities.
Each student will follow one seminar from the following topics : algorithms, security, optimization and artificial intelligence. This seminar is classified as artificial intelligence for the purpose of this requirement.
 When each patient of a kidney exchange program has a preference ranking over its set of compatible donors, questions naturally arise surrounding the stability of the proposedexchanges. We extend recent work on stable exchanges by introducing and underlining therelevance of a new concept of locally stable, or L-stable, exchanges. We showthat locally stable exchanges in a compatibility digraph are exactly the so-called localkernels (L-kernels) of an associated blocking digraph (whereas the stable exchanges arethe kernels of the blocking digraph). Based on these insights, we proposeseveral integer programming formulations for computing an L-stable exchange of maximum size. We conduct numerical experiments to assess the quality of our formulations and to compare the size of maximum L-stable exchanges with the size of maximum stable exchanges. It turns out that nonempty L-stable exchanges frequently exist indigraphs which do not have any stable exchange.
When each patient of a kidney exchange program has a preference ranking over its set of compatible donors, questions naturally arise surrounding the stability of the proposedexchanges. We extend recent work on stable exchanges by introducing and underlining therelevance of a new concept of locally stable, or L-stable, exchanges. We showthat locally stable exchanges in a compatibility digraph are exactly the so-called localkernels (L-kernels) of an associated blocking digraph (whereas the stable exchanges arethe kernels of the blocking digraph). Based on these insights, we proposeseveral integer programming formulations for computing an L-stable exchange of maximum size. We conduct numerical experiments to assess the quality of our formulations and to compare the size of maximum L-stable exchanges with the size of maximum stable exchanges. It turns out that nonempty L-stable exchanges frequently exist indigraphs which do not have any stable exchange.
In this semniar, we will revisit the widely known biclique attack, a technique that has played a significant role in the field of cryptography since its famous attack on the full AES. The discussion will provide a comprehensive overview of the initial attack technique on the AES, detailing the key principles that govern its effectiveness. As we progress, we will discuss the advantages and disadvantages of the biclique attack and explore some of its generalisations and extensions, including applications to other cryptographic primitives, that have emerged over the years.
 Wouter Verbeke
Wouter Verbeke
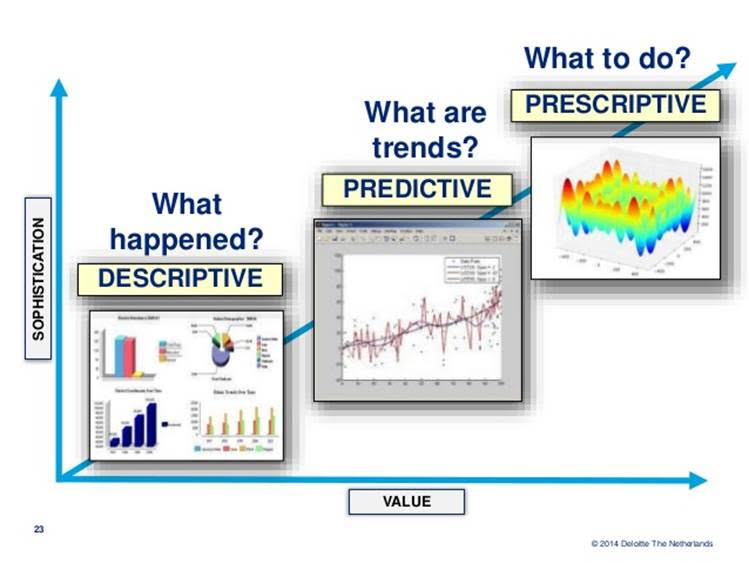 Machine learning is a powerful tool to support business decision-making. For instance, predictive models can be learned from data to anticipate the future and to make informed decisions, with the eventual objective of optimizing the efficiency and effectiveness of business operations. Even better than having predictive models, which tell you what will happen, is to have prescriptive models, which tell you what to do so as to optimize the outcome of interest. To this end, in the field of prescriptive analytics and operations research, simulation models are developed by an human expert modeler in the form of a series of mathematical equations. As an alternative approach, causal machine learning can be adopted to learn to predict the future as a function of the decisions that are made. In other words, causal machine learning models estimate the net effect on the outcome(s) of interest that would be caused by various potential business decisions. As such, these models may directly indicate the optimal decision. In this talk, I will demonstrate the use and need for causal machine learning by discussing on a number business cases. I will discuss on the challenges in estimating causal effects and learning a simulation model from data, and introduce some basic causal machine learning methods.
Machine learning is a powerful tool to support business decision-making. For instance, predictive models can be learned from data to anticipate the future and to make informed decisions, with the eventual objective of optimizing the efficiency and effectiveness of business operations. Even better than having predictive models, which tell you what will happen, is to have prescriptive models, which tell you what to do so as to optimize the outcome of interest. To this end, in the field of prescriptive analytics and operations research, simulation models are developed by an human expert modeler in the form of a series of mathematical equations. As an alternative approach, causal machine learning can be adopted to learn to predict the future as a function of the decisions that are made. In other words, causal machine learning models estimate the net effect on the outcome(s) of interest that would be caused by various potential business decisions. As such, these models may directly indicate the optimal decision. In this talk, I will demonstrate the use and need for causal machine learning by discussing on a number business cases. I will discuss on the challenges in estimating causal effects and learning a simulation model from data, and introduce some basic causal machine learning methods.
 This talk will focus on two graph parameters: stack layouts
and queue layouts of graphs. I will talk about the history of these
two graph parameters, their still not fully understood relationship
and some recent breakthroughs.
This talk will focus on two graph parameters: stack layouts
and queue layouts of graphs. I will talk about the history of these
two graph parameters, their still not fully understood relationship
and some recent breakthroughs.
Isogeny-based cryptography is a branch of cryptography whose security ideally relies on the hardness of finding an isogeny (= a special kind of map) between two given elliptic curves. The earliest constructions go back to 1997, but the field gained full traction in 2016, with the submission of the Supersingular Isogeny Key Encapsulation suite (SIKE) to NIST's ongoing post-quantum cryptography competition. SIKE had many supporters, in part thanks to the existing community of elliptic curve experts working in crypto. The features of SIKE included good performance, low bandwidth requirements, resistance against many attack efforts, and diversification: it was one of the very few proposals not belonging to the "linear algebra with noise" family, which includes all lattice-based and code-based cryptography. However, late July 2022, a few weeks after NIST had advanced SIKE to the fourth round of their competition, in a joint work with Thomas Decru we managed to break it completely, with the most conservative parameter sets falling in under an hour on a standard laptop. In the meantime, follow-up works due to Maino-Martindale and Robert have shown that SIKE cannot be reanimated. The goal of this talk is to explain the attack, discuss some of the "lessons learned" for post-quantum cryptography as a whole, and make a case for the future of isogeny-based cryptography: while SIKE is dead, finding isogenies is still a very hard problem and various promising isogeny-based proposals remain unaffected.

Wouter Castryck works as a research expert at the research group Cosic of the Department of Electrical Engineering at KU Leuven. He is interested in computational aspects of number theory and algebraic geometry, with a focus on applications to cryptography. Most of his recent work was devoted to isogeny-based cryptography, which is an actively studied subbranch of post-quantum cryptography.


Benders decomposition is a method to solve large MIPs but require problems to have a specific structure. Sometimes, we want to apply a Benders-like scheme on problems that do not fit properly. I will first present a case where all is well: designing a public transport network in Canberra. Then, one where had to create a new framework: solid waste management in Bahía Blanca.
 Planning last-mile delivery operations is one of the most crucial tasks faced by e-commerce companies.
If last-mile delivery is carefully designed, not only can customers' expectations be fulfilled, but also urban congestion and noxious emissions can be addressed. However, a smart planning of last-mile delivery operations is particularly challenging because e-commerce companies can rely on razor-thin marginal profits.
E-commerce giants, such as Amazon or JD.com, are investigating new paradigms to run last-mile deliveries. One of the most promising ways to improve the current practices in last-mile delivery is to adopt Unmanned Autonomous Vehicles (UAV), such as drones or self-driving robots.
UAVs complement or replace conventional vehicles, such as vans or cargo-bikes. In this talk we consider deliveries made by a deliveryman that rides a cargo-bike helped by a self-driving robot.
The bike and the robot leave together a central depot and deliver a number of packages. When the robot is empty it can be replenished by the deliveryman. This implies that the robot and the bike might meet during the working shift. When delivery operations are finished, the deliveryman and the robot go back to the depot.
We formally describe and formulate the problem with two Mixed-Integer Linear Programming (MILP) models. The first model is a compact MILP featuring a polynomial number of variables
and constraints. The second MILP builds upon the first model but features an exponential number of constraints. We also propose a set of valid inequalities to tighten the linear relaxation of both
these MILP models and embed these cuts into branch-and-cut algorithms.
We present a genetic algorithm, based on dynamic programming recursions to explore a large neighborhood of solutions and to find high-quality primal solutions of the problem.
We test the proposed branch-and-cut algorithms and the genetic algorithm on real-life instances provided by JD.com and show that the branch-and-cut methods can find optimal solutions
of most of the proposed instances with up to 80 customers.
This work is in collaboration with Ningxuan Kang, Roberto Roberti and Yanlu Zhao
Planning last-mile delivery operations is one of the most crucial tasks faced by e-commerce companies.
If last-mile delivery is carefully designed, not only can customers' expectations be fulfilled, but also urban congestion and noxious emissions can be addressed. However, a smart planning of last-mile delivery operations is particularly challenging because e-commerce companies can rely on razor-thin marginal profits.
E-commerce giants, such as Amazon or JD.com, are investigating new paradigms to run last-mile deliveries. One of the most promising ways to improve the current practices in last-mile delivery is to adopt Unmanned Autonomous Vehicles (UAV), such as drones or self-driving robots.
UAVs complement or replace conventional vehicles, such as vans or cargo-bikes. In this talk we consider deliveries made by a deliveryman that rides a cargo-bike helped by a self-driving robot.
The bike and the robot leave together a central depot and deliver a number of packages. When the robot is empty it can be replenished by the deliveryman. This implies that the robot and the bike might meet during the working shift. When delivery operations are finished, the deliveryman and the robot go back to the depot.
We formally describe and formulate the problem with two Mixed-Integer Linear Programming (MILP) models. The first model is a compact MILP featuring a polynomial number of variables
and constraints. The second MILP builds upon the first model but features an exponential number of constraints. We also propose a set of valid inequalities to tighten the linear relaxation of both
these MILP models and embed these cuts into branch-and-cut algorithms.
We present a genetic algorithm, based on dynamic programming recursions to explore a large neighborhood of solutions and to find high-quality primal solutions of the problem.
We test the proposed branch-and-cut algorithms and the genetic algorithm on real-life instances provided by JD.com and show that the branch-and-cut methods can find optimal solutions
of most of the proposed instances with up to 80 customers.
This work is in collaboration with Ningxuan Kang, Roberto Roberti and Yanlu Zhao
We consider the unlabeled motion-planning problem of m unit-disc robots moving in a simple polygonal workspace of n edges. The goal is to find a motion plan that moves the robots to a given set of m target positions. For the unlabeled variant, it does not matter which robot reaches which target position as long as all target positions are occupied in the end. If the workspace has narrow passages such that the robots cannot fit through them, then the free configuration space, representing all possible unobstructed positions of the robots, will consist of multiple connected components. Even if in each component of the free space the number of targets matches the number of start positions, the motion-planning problem does not always have a solution when the robots and their targets are positioned very densely. In this paper, we prove tight bounds on how much separation between start and target positions is necessary to always guarantee a solution. Moreover, we describe an algorithm that always finds a solution in time O(nlog n + mn + m^2) if the separation bounds are met. Specifically, we prove that the following separation is sufficient: any two start positions are at least distance 4 apart, any two target positions are at least distance 4 apart, and any pair of a start and a target positions is at least distance 3 apart. We further show that when the free space consists of a single connected component, the separation between start and target positions is not necessary.

Irina Kostitsyna is an assistant professor in the Applied Geometric Algorithms group in the Department of Mathematics and Computer Science. Her research interests lie in the field of computational geometry, both in its theoretical and applied aspects. In particular, her main topics of research include geometric algorithms for mobile agents, including path planning and routing; and for programmable matter, including shape reconfiguration problems.
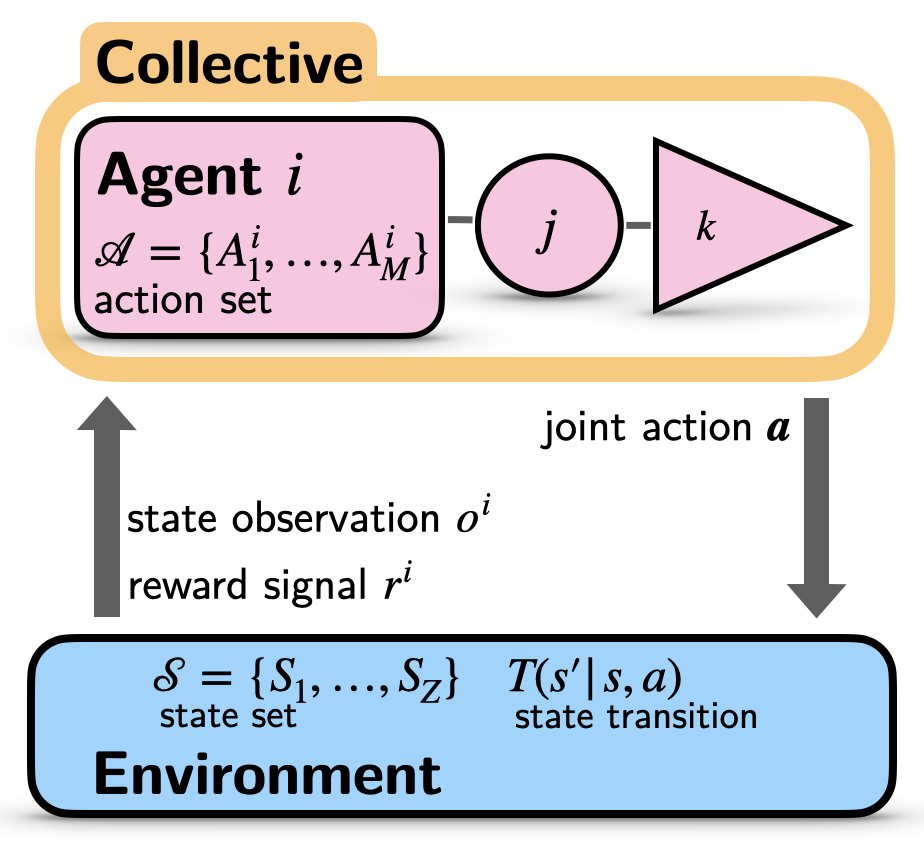
Artificial intelligence research makes the decision-making capabilities of autonomous agents increasingly powerful, using the technique of reinforcement learning. However, little is known about the collective behavior that emerges from and influences a set of multiple reinforcement learning agents. To this end, I present how to efficiently describe the emergent behavior of reinforcement learning agents via dynamical systems theory. The proposed approach has the potential to become a practical, lightweight, and robust tool to create insights about collective learning in uncertain and changing environments.

Wolfram Barfuss is a research scientist at the Tübingen AI Center at the University of Tübingen in Germany. He studied physics (M.Sc. 2015), focusing on complex systems at the University of Erlangen-Nuremberg and University College London. In 2019, he received a doctorate in natural science from the Humboldt University Berlin for his work on learning dynamics and decision paradigms in social-ecological dilemmas. Before joining the University of Tübingen, he was a research fellow in the School of Mathematics at the University of Leeds, the Max Planck Institute for Mathematics in the Sciences in Leipzig, and held guest research appointments at the Stockholm Resilience Centre and Princeton University.
Quantum computers are predicted to break our current (public key) encryption and signature standards, which are based on factoring. To protect our data and devices in a future with quantum computing, a paradigm shift towards new types of cryptography is needed. Such new algorithms, secure against quantum computers, are developed in the field of post-quantum cryptography. In this talk we will look at new quantum-safe (or post-quantum) algorithms that are designed to replace the insecure old standards. The goal is to get an idea of how these algorithms work and what challenges lie ahead in the implementation and deployment of these standards.

Jan-Pieter D'Anvers is a postdoctoral researcher in the COSIC research group from KU Leuven. His research focuses on the design, security and side-channel security of post-quantum cryptography (i.e. cryptography that is secure in the presence of quantum computers) and fully homomorphic encryption (i.e. encryption that allows computation on the encrypted data). He is co-designer of Saber, one of the final candidates in the NIST post-quantum standardization process, an international standardization effort.
Relay attacks pose an important threat in wireless ranging and authentication systems. Distance bounding protocols have been proposed as an effective countermeasure against relay attacks and allow a verifier and a prover to establish an upper bound on the distance between them. In this talk, we will discuss why distance bounding protocols are an interesting security primitive, but also why these protocols are difficult to realise in practice. Next, we will present several design approaches for the secure realisation of distance bounding protocols which have been recently proposed in the literature.

Dr. Ir. Dave Singelée received the Master’s degree of Electrical Engineering and a PhD in Applied Sciences in 2002 and 2008 respectively, both from the KU Leuven (Belgium). He worked as an ICT security consultant at PricewaterhouseCoopers Belgium, and is currently an industrial research manager (IOF) at the research group COSIC. His main research interests are cryptography, security and privacy of wireless communication networks, key management, distance bounding and cryptographic authentication protocols, and security solutions for medical devices.


The dependability of distributed systems often critically depends on the underlying communication network, realized by a set of routers. To provide high availability, modern routers support local fast rerouting of flows: routers can be preconfigured with conditional failover rules which define to which port a packet arriving on this incoming port should be forwarded deterministically depending on the status of the incident links only. As routers need to react quickly, they do not have time to learn about remote failures. My talk revolves around the fundamental question whether and how local fast rerouting mechanisms can be configured such that packets always reach their destination even in the presence of multiple failures, as long as the underlying network is still connected. I will show that this algorithmic problem is related to the field of disconnected cooperation, and offers a number of challenging research questions -- and sometimes surprising results. In particular, I will give an overview of state-of-the-art algorithmic techniques for different realistic graph classes (from dense datacenter topologies to sparse wide-area networks) and discuss lower bounds and impossibility results. While the main focus of the talk will be on deterministic algorithms, we will also take a glimpse at the power of randomization.
Stefan Schmid is a Full Professor at the Technical University of Berlin, Germany, working part-time for the Fraunhofer Institute for Secure Information Technology (SIT). MSc and Ph.D. at ETH Zurich, Postdoc at TU Munich and the University of Paderborn, Senior Research Scientist at T-Labs in Berlin, Associate Professor at Aalborg University, Denmark, and Full Professor at the University of Vienna, Austria. Stefan Schmid received the IEEE Communications Society ITC Early Career Award 2016 and an ERC Consolidator Grant 2019. His current research interests revolve around the fundamental and algorithmic problems arising in networked systems.
 Jens Hermans is currently the CEO of nextAuth, a spin-off company of KU Leuven on secure and user friendly mobile authentication that he co-founded in 2019. Before that, he was a researcher at the COSIC group, KU Leuven (PhD in 2012). His main research interest is security and cryptography for the real world: the analysis and design of protocols, human-computer interaction in security and, in general, overall security architectures and solutions for challenging applications such as authentication and voting.
Jens Hermans is currently the CEO of nextAuth, a spin-off company of KU Leuven on secure and user friendly mobile authentication that he co-founded in 2019. Before that, he was a researcher at the COSIC group, KU Leuven (PhD in 2012). His main research interest is security and cryptography for the real world: the analysis and design of protocols, human-computer interaction in security and, in general, overall security architectures and solutions for challenging applications such as authentication and voting.
 Let P be a set of n points in R^3 in general position, and let RCH(P) be the rectilinear convex hull of P. In this talk we show how we obtain an optimal O(n log n)-time and O(n)-space algorithm to compute RCH(P). We also obtain an efficient O(n\log^2 n)-time and O(n log n)-space algorithm to compute and maintain the set of vertices of the rectilinear convex hull of P as we rotate R^3 around the z-axis. Finally, we study some properties of the rectilinear convex hulls of point sets in R^3.
Let P be a set of n points in R^3 in general position, and let RCH(P) be the rectilinear convex hull of P. In this talk we show how we obtain an optimal O(n log n)-time and O(n)-space algorithm to compute RCH(P). We also obtain an efficient O(n\log^2 n)-time and O(n log n)-space algorithm to compute and maintain the set of vertices of the rectilinear convex hull of P as we rotate R^3 around the z-axis. Finally, we study some properties of the rectilinear convex hulls of point sets in R^3.

The Balanced Minimum Evolution Problem (BMEP) is a NP-hard network design problem that consists of finding a minimum length unrooted binary tree (also called a phylogeny) having as a leaf-set a specific set of items encoding molecular sequences. The optimal solution to the BMEP (i.e., the optimal phylogeny) encodes the hierarchical evolutionary relationships of the input sequences. This information is crucial for a multitude of research fields, ranging from systematics to medical research, passing through drug discovery, epidemiology, ecology, biodiversity assessment and population dynamics. In this talk, we introduce the attendant to the problem and its applications as well as to its connections with other areas such as data compression and information entropy. We review the most important results achieved so far and the challenges that still remain to be addressed.
 When individuals face collective action problems, their expectations about the current and future behavior of others are fundamental to trigger cooperation. There is a catch, however: in the context of global public goods games, it can be hard to perceive the overall behaviors of others, and, in fact, individuals often incur social perception biases — i.e., over- or under-estimating the actual cooperation levels in a population. One pressing domain where such biases can have an impact is climate change, as people typically underestimate the pro-climate positions of others. To design incentives that enable cooperation and a sustainable future one must consider how social perception biases affect collective action. In this talk, I will discuss a theoretical model — based on game theory and best-response learning dynamics — that allows us to investigate the effect of social perception bias in (non-linear) public goods games. We will see that different types of bias play a distinct role in cooperation dynamics. False uniqueness (underestimating own views) and false consensus (overestimating own views) can both explain why communities get locked in suboptimal states. Furthermore, we will discuss how biases also impact the effectiveness of typical monetary incentives, such as fees. This will allow us to discuss, finally, how targeting biases, e.g., by changing the information available to individuals, can comprise a fundamental mechanism to prompt collective action.
When individuals face collective action problems, their expectations about the current and future behavior of others are fundamental to trigger cooperation. There is a catch, however: in the context of global public goods games, it can be hard to perceive the overall behaviors of others, and, in fact, individuals often incur social perception biases — i.e., over- or under-estimating the actual cooperation levels in a population. One pressing domain where such biases can have an impact is climate change, as people typically underestimate the pro-climate positions of others. To design incentives that enable cooperation and a sustainable future one must consider how social perception biases affect collective action. In this talk, I will discuss a theoretical model — based on game theory and best-response learning dynamics — that allows us to investigate the effect of social perception bias in (non-linear) public goods games. We will see that different types of bias play a distinct role in cooperation dynamics. False uniqueness (underestimating own views) and false consensus (overestimating own views) can both explain why communities get locked in suboptimal states. Furthermore, we will discuss how biases also impact the effectiveness of typical monetary incentives, such as fees. This will allow us to discuss, finally, how targeting biases, e.g., by changing the information available to individuals, can comprise a fundamental mechanism to prompt collective action.
Many discrete optimization problems amount to select a feasible subgraph of least weight. We consider in this paper the context of spatial graphs where the positions of the vertices are uncertain and belong to known uncertainty sets. The objective is to minimize the sum of the distances in the chosen subgraph for the worst positions of the vertices in their uncertainty sets. We first prove that these problems are NP-hard even when the feasible subgraphs consist either of all spanning trees or of all s-t paths. In view of this, we propose en exact solution algorithm combining integer programming formulations with a cutting plane algorithm, identifying the cases where the separation problem can be solved efficiently. We also propose two types of polynomial-time approximation algorithms. The first one relies on solving a nominal counterpart of the problem considering pairwise worst-case distances. We study in details the resulting approximation ratio, which depends on the structure of the metric space and of the feasible subgraphs. The second algorithm considers the special case of s-t paths and leads to a fully-polynomial time approximation scheme. Our algorithms are numerically illustrated on a subway network design problem and a facility location problem.

Michaël Poss graduated in Mathematics from the Université Libre de Bruxelles, and in Operational Research from the University of Edinburgh. His thesis was done at the GOM research group from the Université Libre de Bruxelles, under the supervision of Bernard Fortz, Martine Labbé, and François Louveaux. During my PhD, he spent time in Rio de Janeiro, working at the Universidade Federal do Rio de Janeiro and at the CEPEL, working with Claudia Sagastizabal and Luciano Moulin. After his thesis was defended in Feburary 2011, he spent a couple of months at the Universidade de Aveiro, followed by a postdoctoral stay at the CMUC from the Universidade de Coimbra. He was a CNRS researcher at Heudiasyc from October 2012 to January 2015 and joined the LIRMM in February 2015. He has been a senior researcher (directeur de recherche) since 2020.

A cops and robber game, or a search game, consists in locating an intruder (the robber) by placing and moving searchers (the cops) on the vertices of the graph. An edge is cleaned when its two vertices are simultaneously occupied by searchers. A search strategy is monotone if no edge recontamination is permitted. It is well known that depending on the ability of the intruder, laziness or agileness, the numbers of required searchers to clean the graph (with a monotone strayegy) respectively corresponds to the treewidth and pathwidth parameters. In this talk, we will consider the connected variant of these search games, where the clean territory is required to be connected. It is known that a monotone search against an agile intruder, satisfying connectivity constraint requires to double the number of searchers. The connected search number against an agile intruder defines the connected pathwidth parameter. Recently, it has been proved that for every fixed k, deciding whether the connected pathwidth of a graph is at most k is polynomial time solvable (belongs to the complexity the class XP). We will sketch a fixed parameter (FPT) algorithm for that problem. Beside connected pathwidth, one can define the connected treewidth by considering a connected search against a lazy intruder. It turns out that in this case the price of connectivity is unbounded. We can show that even for series-parallel graphs (aka treewidth 2 graphs), the connected search number can be arbitrarily large (see figure). One can observe that connected pathwidth and connected treewidth are not closed undertone minor relation but are closed under edge contraction. We show that for every k at least 2, the number of (contraction) obstructions is infinite and we will provide a full (and finite) description of the obstruction set for k=2. We let open the question whether deciding the connected treewidth is fixed parameter tractable, but (depending on the time) we will describe a polynomial time algorithm for series-parallel graphs.

Christophe Paul is a a full-time researcher at the CNRS, with the ALgorithms for Graphs and COmbinatorics group (AlGco) of the LIRMM. His research focusses on graph theory and algorithms and more specifically on graph decomposition techniques, combinatorial algorithms and fixed parameterized algorithms. He also has interests in computational complexity, combinatorics, computational biology and many others in computer science and discrete mathematics

Fare evasion in transit networks causes significant losses to the operators. In order to decrease evasion rates and reduce these losses, transportation companies conduct fare inspections to check traveling passengers for valid tickets. In this talk, we will discuss a bilevel optimization model for distributing such inspections in the network while taking into account the passengers' reaction. We will report on theoretical insights, a resulting collaboration with transportation authorities, and give an outlook on future research.

Jannik Matuschke is an Assistant Professor of Operations Management at KU Leuven. Before joining KU Leuven in 2019, he was a lecturer in Operations Research at Technische Universität München. Earlier, he was a postdoc at Universidad de Chile and a visiting professor at the University of Rome "Tor Vergata". He obtained his PhD in Mathematics at TU Berlin in 2013. Jannik's research focusses on combinatorial optimization and graph algorithms, in particular network and scheduling problems, approximation algorithms, and applications in logistics and transportation.


Computing the diameter of a graph (maximum number of edges on a shortest path) is a fundamental graph problem with countless applications in computer science and beyond. Unfortunately, the textbook algorithm for computing the diameter of an n-vertex m-edge graph takes O(nm)-time. This quadratic running-time is too prohibitive for large graphs with millions of nodes.
The radius and diameter of a graph are part of the basic global parameters that allow to apprehend the structure of a practical graph. More broadly, the eccentricity of each node, defined as the furthest distance from the node, is also of interest as a classical centrality measure. It is tightly related to radius which is the minimum eccentricity and to diameter which is the maximum eccentricity.
On the one hand, efficient computation of such parameters is still theoretically challenging as truly sub-quadratic algorithms would improve the state of the art for other ``hard in P'' related problems such as finding two orthogonal vectors in a set of vectors or testing if one set in a collection is a hitting set for another collection. A sub-quadratic diameter algorithm would also refute the strong exponential time hypothesis (SETH) and would improve the state of the art of SAT solvers. I will explain the reduction between deciding if the diameter of a split graph is 2 or 3 and a subexponential algorithm for SAT. Then I will propose a kind of dichotomy result for split graphs trying to fix the boarder between linear and quadratic algorithms.
On the other hand, a line of practical algorithms has been proposed based on performing selected Breadth First Search traversals (BFS) allowing to compute the diameter of very large graphs. However, such practical efficiency is still not well understood. We propose a notion of certificate that helps to capture the efficiency of these practical algorithms.
I will finish with a survey of the practical algorithms that compute shortest paths in road networks and some open problems involving dynamic networks.

Michel Habib is professor emeritus in Computer Science at University Paris Diderot - Paris 7, UFR d’Informatique. He is a member of both the research group Algorithms and discrete structures and the INRIA Paris research team Gang. His research is mainly focused on classic algorithms on discrete structures with special interest for graphs and orders, including:
The speaker is hosted by Jean-Paul Doignon.
May 23th, 2019, 12:30 PM, room: Forum F
Let P be a set of n points in the plane. In the traditional geometric algorithms view, P is given as an unordered sequence of locations (usually pairs of x and y coordinates). There are many interesting and useful structures that one can build on top of P: the Delaunay triangulation, Voronoi diagram, well-separated pair decomposition, quadtree, etc. These structures can all be represented in O(n) space but take Omega(n log n) time to construct on a Real RAM, and, hence, contain information about P that is encoded in P but cannot be directly read from P.
In this talk I will explore the question how much information about the structure of a set of points can be derived from their locations, especially when we are *uncertain* about the locations of the points.

Maarten Löffler is currently an assistant professor at Utrecht University. He has been a post-doc researcher at the Bren School of information and computer sciences of the University of California, Irvine. He was a PhD-student at Utrecht University.
The speaker is hosted by the Algorithms Group.
Nowadays, there are applications in which the data are modelled best not as persistent tables, but rather as transient data streams. In this keynote, we discuss the limitations of current machine learning and data mining algorithms. We discuss the fundamental issues in learning in dynamic environments like learning decision models that evolve over time, learning and forgetting, concept drift and change detection. Data streams are characterized by huge amounts of data that introduce new constraints in the design of learning algorithms: limited computational resources in terms of memory, processing time and CPU power. In this talk, we present some illustrative algorithms designed to taking these constrains into account. We identify the main issues and current challenges that emerge in learning from data streams, and present open research lines for further developments.

João Gama is an Associate Professor at the University of Porto, Portugal. He is a senior researcher and member of the board of directors of the LIAAD, a group belonging to INESC Porto. He is Director of the master Data Analytics. He serves as member of the Editorial Board of MLJ, DAMI, TKDE, NGC, KAIS, and IDA. He served as Chair of ECMLPKDD 2005 and 2015, DS09, ADMA09 and a series of Workshops on KDDS and Knowledge Discovery from Sensor Data with ACM SIGKDD. His main research interest is in knowledge discovery from data streams and evolving data. He is the author of a recent book on Knowledge Discovery from Data Streams. He has extensive publications in the area of data stream learning.
The speaker is hosted by the Machine Learning Group.
In this talk, I will survey recent approaches/results to obtain physical security against side-channel attacks exploiting leakages, such as an implementation's power consumption. After a brief introduction and motivation, I'll describe how these attacks proceed (i.e., the so-called standard DPA setting) and why purely hardware-level (practical, heuristic) countermeasures alone cannot solve the problem. I will then discuss how the impact of hardware-level countermeasures can be amplified thanks an algorithmic-level countermeasure called masking, how this amplification can be formally analyzed, and the implementation challenges that physical defaults can imply for the secure implementation of masking. I will conclude by discussing the need of an open approach to physical security, and the interest of re-designing cryptographic algorithms and protocols for this purpose.

Francois-Xavier Standaert received the Electrical Engineering degree and PhD degree from the Universite catholique de Louvain, respectively in 2001 and 2004. In 2004-2005, he was a Fulbright visiting researcher at Columbia University, Department of Computer Science, Crypto Lab and at the MIT Medialab, Center for Bits and Atoms. In 2006, he was a founding member of IntoPix s.a. From 2005 to 2008, he was a post-doctoral researcher of the Belgian Fund for Scientific Research (FNRS-F.R.S.) at the UCL Crypto Group. Since 2008 (resp. 2017), he is associate researcher (resp. senior associate researcher) of the Belgian Fund for Scientific Research (FNRS-F.R.S). Since 2013 (resp. 2018), he is associate professor (resp. professor) at the UCL Institute of Information and Communication Technologies, Electronics and Applied Mathematics (ICTEAM). In 2011, he was awarded a Starting Independent Research Grant by the European Research Council. In 2016, he has been awarded a Consolidator Grant by the European Research Council. From 2017 to 2020, he will be board member (director) of the International Association for Cryptologic Research (IACR). His research interests include cryptographic hardware and embedded systems, low power implementations for constrained environments (RFIDs, sensor networks, ...), the design and cryptanalysis of symmetric cryptographic primitives, physical security issues in general and side-channel analysis in particular.
The speaker is hosted by the Quality and Security of Information Systems Group.
Optimization models for Air Traffic Flow Management (ATFM) select, for each flight, suitable trajectories with the aim of reducing congestion of both airports and en-route sectors, and maximizing the Air Traffic Management system efficiency. Recent models try to include as accurate as possible information on airspace capacity as well as on Airspace Users route preferences and priorities, as suggested by recent SESAR (Single European Sky ATM Research) programs. In this direction, we analyze flight trajectories queried from Eurocontrol DDR2 data source. We learn homogeneous trajectories via clustering, and we apply data analytics (mainly based on tree classifiers, support vector machines and multiple regression) to explore the relation between grouped trajectories and potential choice-determinants such as length, time, en-route charges, fuel consumption, aircraft type, airspace congestion etc. The associations are evaluated and the predictive value of determinants is validated and analyzed. For any given origin-destination pair, this ultimately leads to determining a set of flight trajectories and information on related Airspace Users' preferences that feed optimization models for ATFM.

Luigi De Giovanni is Associate Professor of Operations Research at University of Padua (Italy), Department of Mathematics "Tullio Levi-Civita". He received the Master Degree cum laude in Computer Engineering from "Politecnico" University of Turin (Italy) in 1999, and the PhD degree in Computer and System Engineering from the same university in 2004. He has been visiting PhD student at Université Libre de Bruxelles (ULB) in 2003. He has been post-doc researcher at the Computer Science Department of ULB from 2004 to 2006, and at the Computer and Management Engineering Department of Marche "Politecnica" University in Ancona (Italy) from 2006 to 2007. He has been Assistant Professor of Operations Research at University of Padua from October 2007 to September 2018. His main research interests cover mathematical programming and meta-heuristic methods and models for combinatorial optimization and their application to telecommunication network configuration, transportation, logistics, scheduling, air traffic and airport optimization.
The speaker is hosted by GOM.

Explaining the emergence of cooperation is one of the biggest challenges science faces today. Indeed, cooperation dilemmas occur at all scales and levels of complexity, from cells to global governance. Theoretical and experimental works have shown that status and reputations can provide solutions to the cooperation conundrum. These features are often framed in the context of indirect reciprocity, which constitutes one of the most elaborate mechanisms of cooperation discovered so far. By helping someone, individuals may increase their reputation, which can change the predisposition of others to help them in the future. The reputation of an individual depends, in turn, on the social norms that establish what characterises a good or bad action. Such norms are often so complex that an individual’s ability to follow subjective rules becomes important. In this seminar, I will discuss a simple evolutionary game capable of identifying the key pattern of the norms that promote cooperation, and those that do so at a minimum complexity. This combination of high cooperation and low complexity suggests that simple moral principles, and informal institutions based on reputations, can elicit cooperation even in complex environments.

Francisco C. Santos is an Associate Professor of the Department of Computer Science and Engineering of IST, University of Lisbon (Portugal). He is interested in applying scientific computing and modelling tools to understand collective dynamics in social and life sciences. He has been working on problems related to the evolution of cooperation, the origins of social norms, network science, and environmental governance, among others. He obtained a PhD in computer science from the Université Libre de Bruxelles in 2007.
The speaker is hosted by MLG.

Hubbing is commonly used in airlines, cargo delivery and telecommunications networks where traffic from many origins to many destinations are consolidated at hubs and are routed together to benefit from economies of scale. Each application area has its own specific features and the associated hub location problems are of complex nature. In the first part of this talk, I will introduce the basic hub location problems, summarize important models and results and mention the shortcomings of these in addressing real life situations. In the second part, I will introduce new variants of the hub location problem that incorporate features such as hierarchical and multimodal networks, service of quality constraints, generalized allocation strategies and demand uncertainty. I will conclude the talk with an ongoing work on a joint problem of hub location, network design and dimensioning.

Hande Yaman received her B.S. and M.S. degrees in Industrial Engineering from Bilkent University, and her Ph.D. degree in Operations Research from Universite Libre de Bruxelles. She joined the Department of Industrial Engineering at Bilkent University in 2003. She spent a year as a visiting researcher at CORE, Universite catholique de Louvain. Her research interests are in exact methods for mixed integer programming with applications in production planning, logistics, and network design.
The speaker is hosted by GOM.

Mixing layers, such as MixColumns in the AES, are an essential ingredient that can be found in the round function of most modern block ciphers and permutations. We study a generalization of the mixing layer in Keccak-f, the permutation underlying the NIST standard SHA-3 and the authenticated encryption schemes Keyak and Ketje. We call this generalization column-parity mixing layers and investigate their algebraic and diffusion properties and implementation cost. We demonstrate their competitiveness by presenting a fully specified 256-bit permutation with strong bounds for differential and linear trails.

Joan Daemen, who obtained his PhD in cryptography at the COSIC research group of the KULeuven, is a Belgian cryptographer who co-designed the Rijndael encryption scheme which was selected by the NIST as the Advanced Encryption Standard (AES), as well as the Keccak cryptographic hashing algorithm which was selected also by the NIST as the new SHA-3 standard hash function. He is also the author of many other symmetric cryptographic primitives. In 2017 Joan Daemen won the Levchin Prize for Real World Cryptography. Joan Daemen divides his time between the Institute for Computing and Information Sciences at the Radboud University and STMicroelectronics in Belgium.
The speaker is hosted by QualSEC.
In the standard model of computation often taught in computer science courses one identifies elementary operations and counts them in order to obtain the runtime. However, given the complexity of computing hardware, this measure often does not correlate well with actual observed runtime on a computer; accessing n items sequentially or randomly typically have runtimes that differ by several orders of magnitude. In this talk I will present the cache-oblivious model of computation, a model that was introduced by Prokop in 1999 and is relatively easy to reason with, by modeling the multilevel caches that are a defining feature of the cost of modern computation. After presenting the model, several data structure and algorithms that illustrate design techniques to develop cache-obliviously optimal structures will be presented.
The speaker is hosted by the Algorithms Group.
